
本文来自微信公众号:APPSO (ID:appsolution),作者:appso,原文标题:《OpenAI 和 Grok 都在卷的 “深度检索”,Perplexity 推出了免费版,实测怎么样》,题图来自:AI生成
接入DeepSeek R1之后,Perplexity总算在本职业务上有所更新了,推出了“Deep Research”深度研究。要知道在此之前,它比较大的动作是接入购物功能……
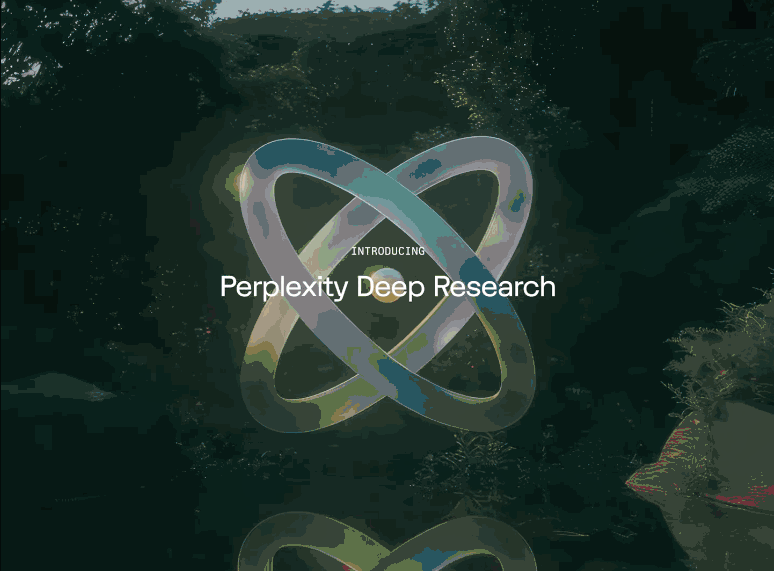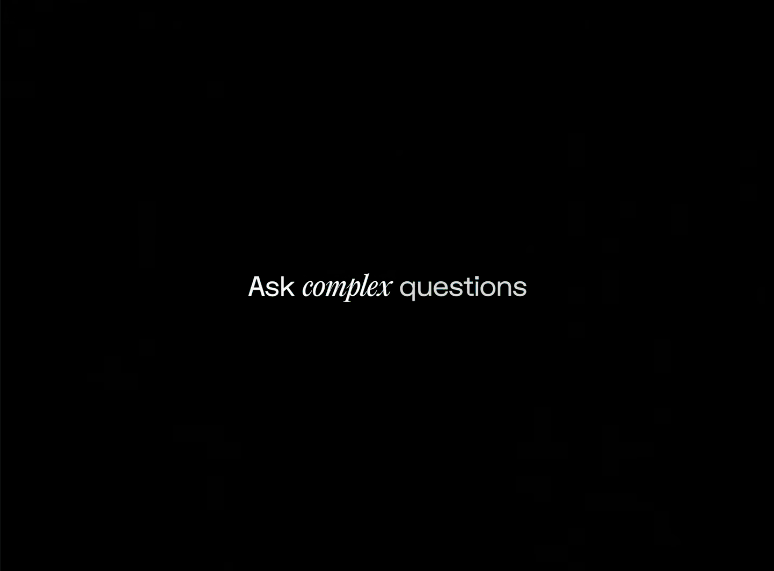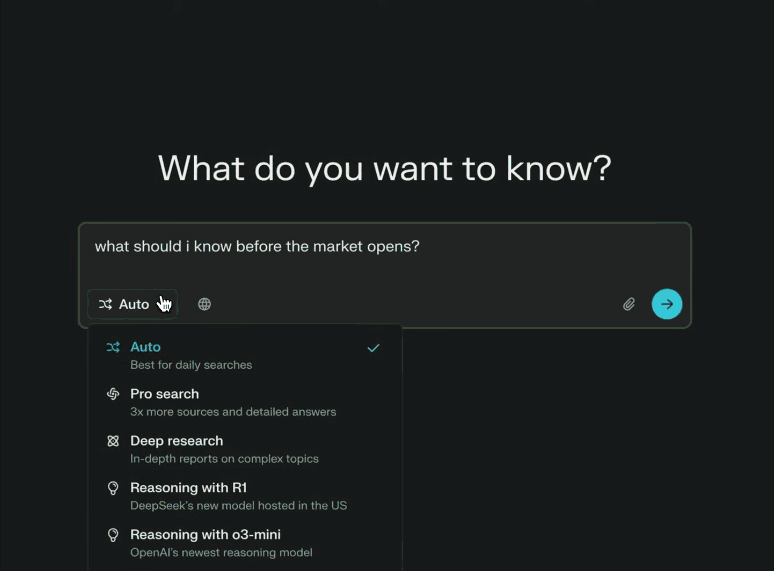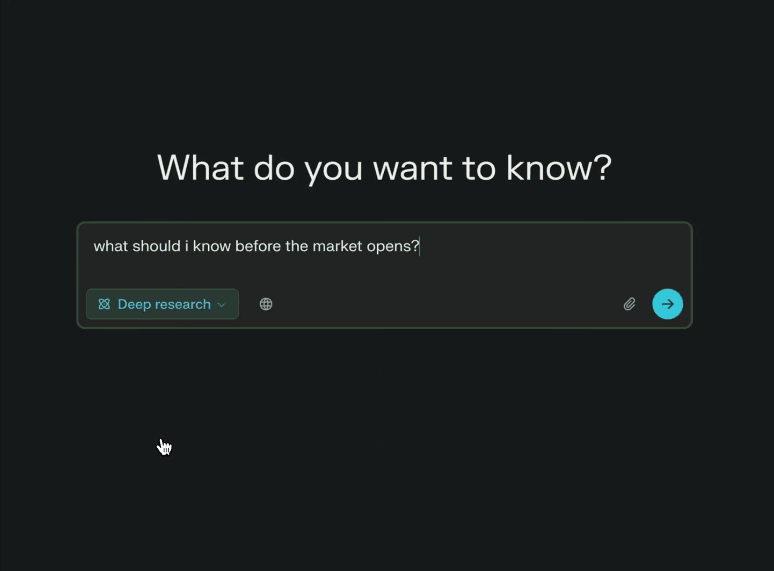
“深度研究”是对标OpenAI的Deep Research的模式,主打深度检索、专业输出。在Humanity’s Last Exam上获得了21.1%的准确率,远高于Gemini Thinking、o3-mini、o1、DeepSeek-R1和许多其他领先模型。这个测试包含3,000多个问题,涵盖100多个学科,从数学和科学到历史和文学,被视为人工智能系统的综合基准。
新功能已经全量推送,注意:免费用户每天只有五次试用。
指路:https://www.perplexity.ai/
既然说是“深度研究”,那么为了区别于以往的常规模式测试,我们在问题设计上有所调整,直接上难度,重点检验一下它是不是真的到了能出报告的地步。
基本面测试,升级了但没完全升
这意味着问题艰深、资料保有量大、需要在输出时体现报告逻辑——所有的提问都要满足这样的要求。
【引用权威性】:2023年诺贝尔经济学奖得主的主要理论贡献是什么?
这里主要考察Deep Research的信息准确性、引用权威性。给定的范围很明确了:2023年、诺贝尔经济学奖,对象基本是唯一的。
这一年的经济学诺奖得主是克劳迪娅·戈尔丁,她的研究横跨了美国200年间的数据,性别差异如何影响收入和就业率。